Problem Statement
모든 소셜 미디어 및 이커머스 회사들이 성장하면서 디지털 광고의 중요성이 그 어느때보다 높아졌고 그에 따라 대다수의 기업들은 디지털 광고에 상당한 투자하고 있다. 모든 기업들은 광고 클릭 이벤트를 추적하고 통계를 내서 광고에 예산을 좀 더 효율적으로 할당하기를 원한다. 따라서 광고 클릭을 정확하게 추적하는건 굉장히 중요한 일이다.
또한 하루에 10억개의 광고 클릭이 발생하고 총 200만개 이상의 광고가 발생한다고 가정하면 데이터 양 또한 굉장히 많을 것이다. 본 포스팅에서는 주요 2가지 유즈케이스에 대해 살펴본다.
- 최근 M분동안 특정 광고의 클릭 이벤트 개수를 구한다.
- 최근 M분동안 가장 클릭이 많이 된 N개의 광고를 구한다.
여기에는 우리가 다뤄야 할 몇가지 엣지케이스가 존재한다.
- 중복된 이벤트가 없어야 한다.
- 이벤트들은 예상보다 늦게 도착할 수 있다.
- 시스템의 여러 부분이 다운될 수 있으므로 복구에 대한 시나리오를 고려해야 한다.
시작하기 전 아래의 상황을 가정해보자.
- DAU 10억
- 각 사용자가 매일 하나의 광고를 클릭하므로 일일 광고 클릭수는 10억회이다.
- 광고 클릭 QPS = 10^9 / 10^5 초 = 10,000 QPS
- 최대 QPS가 평균 QPS의 5배라고 가정하고 최대 QPS는 50k이다.
- 하나의 광고 클릭 이벤트가 0.1KB의 용량을 차지한다고 가정하면 하루에 100GB, 한달에 3TB의 용량이 필요하다.
이제 위에서 말한 유즈케이스에 대해 API디자인 관점에서 생각해본다. 그리고 고수준의 데이터 모델링 또한 진행한다.
Query API Design
API-1. Aggregate the number of clicks of ad-id in the last M minutes
GET /v1/ads/{ad_id}/aggregated_count
Query Params:
- start_time: 기본값으로 현재 시간 - 1분을 가진다.
- to_time: 기본값으로 현재 시간을 가진다.
- filter_identifier: 옵셔널 필드이다. 예를 들어 filter=001인 경우 IP주소에 따라 필터링한다는 의미이다.
Response: 주어진 ad_id에 해당하는 이벤트 개수를 반환한다.
- ad_id: 광고 식별자
- count: 특정 광고 클릭 횟수
API-2. Return TOP N clicked Ad-Ids int the last M minutes
GET /v1/ads/top_clicked_ads
Query Params:
- start_time: 기본값으로 현재 시간 - 1분을 가진다.
- to_time: 기본값으로 현재 시간을 가진다.
- n: 조회할 광고 개수로써 기본값 10을 가진다.
- filter_identifier: 옵셔널 필드이다. 예를 들어 filter=001인 경우 IP주소에 따라 필터링한다는 의미이다.
Response: 주어진 ad_id에 해당하는 이벤트 개수를 반환한다.
- ad_ids: 광고 식별자 리스트
Data Model
이제 실제 데이터 모델링을 진행해본다. 실무에서는 예제보다 많은 필드를 가지고 있겠지만 본 포스팅에서는 주제에 부합하는 적은 필드만 가지고 있다. 다음은 현재 고려해볼 수 있는 로우 데이터 예제이다.

광고 클릭 이벤트가 1분마다 집계된다는 가정하에 빠른 API응답을 위해 집계된 형식으로 데이터를 저장하는것 또한 중요하다.

필터를 적용하여 쿼리할 때 많은 연산이 발생하지 않게 하기 위해 로우 데이터를 특정 포맷에 맞게 저장하는것 또한 필요하다. 우리는 모든 ad_id 및 click_minute에 대해 filter_id별로 그룹핑하고 집계된 수를 저장해야한다.

이제 모든 filter_config를 별도의 테이블에 포함시킬 수 있다.
Where to store all this data?
우리의 유즈케이스에 맞는 데이터베이스를 선택하는것은 굉장히 중요하다. 이는 데이터의 읽기 작업이 많은지, 쓰기 작업이 많은지 또는 둘다인지와 같이 많은 요소들에 따라 달라진다. 또한 통계 쿼리(SUM, COUNT)가 많은 경우 OLAP 데이터베이스가 나을수도 있다. 우리는 로우 데이터, 집계 데이터 2가지 종류의 데이터가 있다.
로우 데이터 입장에서 위에서 이야기했듯이 우리는 피크타임 50K QPS에 근접하는 트래픽을 가지고 있고 이는 쓰기 작업이 많다는 것을 의미한다. 그리고 우리의 API에는 많은 통계 관련 쿼리가 필요하다. 또한 데이터의 양이 지속적으로 증가할 것이기 때문에 확장성있는 분산 데이터베이스가 필요하다.
이러한 경우 Cassandra와 같은 NoSQL 데이터베이스는 쓰기가 많은 시스템에 최적화되어있고 쉽게 확장가능하기 때문에 좋은 선택지가 될 수 있다.
로우 데이터와 집계 데이터의 유일한 차이점은, 집계 데이터의 경우 대시보드를 통해 자주 쿼리되기 때문에 읽기 작업이 많다는 점이다. Cassandra를 사용하면 집계된 데이터를 잘 다룰 수 있다.
추가로 로우 데이터에 대한 마이그레이션 서비스도 지원해야 한다. 로우 데이터는 자주 쿼리되지 않으며 데이터 사이언스나 머신러닝 엔지니어가 분석 목적으로만 사용한다. 따라서 특정 기간 이후 Cold-storage로 데이터를 이관하는것을 고려해야한다.
High-Level Design

다이어그램에 표시된 모든 구성 요소를 살펴보기전에 몇가지 중요한 질문을 해결해야한다.
Q1. 로우 데이터가 집계 데이터의 데이터베이스를 나눈 이유는 무엇인가?
로우 데이터의 경우 백업본으로 취급되기 때문에 어떠한 변형없이 데이터를 저장하는것이 낫다. 그리고 만약 데이터를 스트리밍하는 서비스에 문제가 생겼을 경우 해당 데이터를 통해 언제든지 백업을 진행할 수도 있다.
Q2. 두번째 큐가 필요한 이유는 무엇인가? Data Aggregation Service에서 직접 Aggregation Database로 데이터를 밀어넣으면 안되나?
우리는 정확히 한 번 처리되는 시스템이 필요하다. Kafka Streams 또는 Apache Flink와 같은 유명한 스트리밍 서비스는 2PC 커밋 프로토콜을 사용하여 정확히 한 번 처리할 수 있는 기능을 가지고 있다.
이제 Aggregation Service에 대해 깊게 살펴보자. 해당 서비스를 구현하기 위해 Map Reduce 를 사용하는것은 좋은 선택지가 될 수 있다. Map Reduce는 Map/Aggregator/Reduce 총 3개의 노드를 가지고 있다. 각 노드는 하나의 작업만 담당하며 결과를 이후의 노드로 전송한다.
Map Node
맵 노드는 필요한 경우 모든 종류의 데이터 변환을 처리하고 ad_id를 기반으로 광고 이벤트를 특정 집계 노드로 필터링하거 라우팅해준다. 필터링과 라우팅은 일반적으로 해시 함수이며 동일한 ad_id에 대해서는 동일한 Aggregate Node로 도달하는것을 보장한다. 만약 동일한 ad_id가 다른 Aggragate Node로 라우팅된다면 정확성을 보장할 수 없다.
Aggregator Node
어그리게이터 노드는 메모리에서 매분마다 광고 클릭 이벤트를 계산할 수 있다. 상위 100개 광고 클릭 이벤트와 같은 유즈케이스를 지원하려면 인메모리 힙이 필요할수도 있다.
Reduce Node
리듀스 노드는 모든 어그리게이터 노드의 결과를 단일 결과 형식으로 줄인 다음 다른 Kafka 큐에 쓰여지고 결국 Aggregator Database에 저장된다.
아래의 그림은 맵 리듀스의 흐름을 간단하게 보여준다.
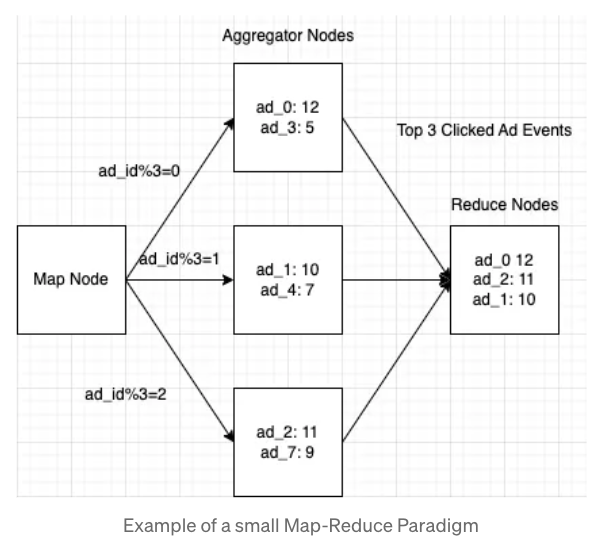
여기에서 논의해야할 주요 사항 중 하나는 맵 리듀스를 사용하여 필터링하는 기준을 설정하는것이다. 이전 섹션에서 우리는 모든 필터를 나타내기 위해 사전에 정의된 filter_id가 있다고 했다.
우리는 사전에 정의한 필터링 기준으로 데이터를 집계해야한다. 여기에서 집계된 데이터란 fact-data가 되고 필터는 dimensional-data가 된다. 이러한 스키마를 star-schema라고 부른다.
이 접근 방식의 문제점은 필터가 많으면 많을수록 집계를 많이 정의해야한다는 것이다. 그런 경우 API서비스의 모든 요청을 필터링하고 Apache Pinot과 같은 OLAP 데이터베이스를 사용하여 각 읽기 요청을 최적화하여 처리하는것이 낫다.
Design Deep Dive
지금까지 우리는 시스템에서 작동하는 모든 구성 요소를 살펴보았고 각 시스템의 명확한 기능을 정의했다. 이제 우리는 시스템이 이러한 것들을 정확히 어떻게 달성할 수 있는지 조금 더 깊이 들어가야한다. 이제부터 제품의 핵심 설계가 시작된다.
Q. Aggregation Service에 문제가 발생하면 어떻게 되나?
로우 데이터가 저장된 데이터베이스에서 집계 데이터가 저장된 데이터베이스로 데이터를 복구하는 흐름이 필요하다. 이러한 경우 각 서비스에서 발생한 문제가 타 서비스로 전파되길 원치 않으므로 별도의 서비스로 분리하길 권장한다. 이는 배치 잡이 될수도 있고 필요할 때마다 실행할 수 있는 커맨드가 될수도 있다.
여기까지 디자인을 다시 그려보면 다음과 같다.
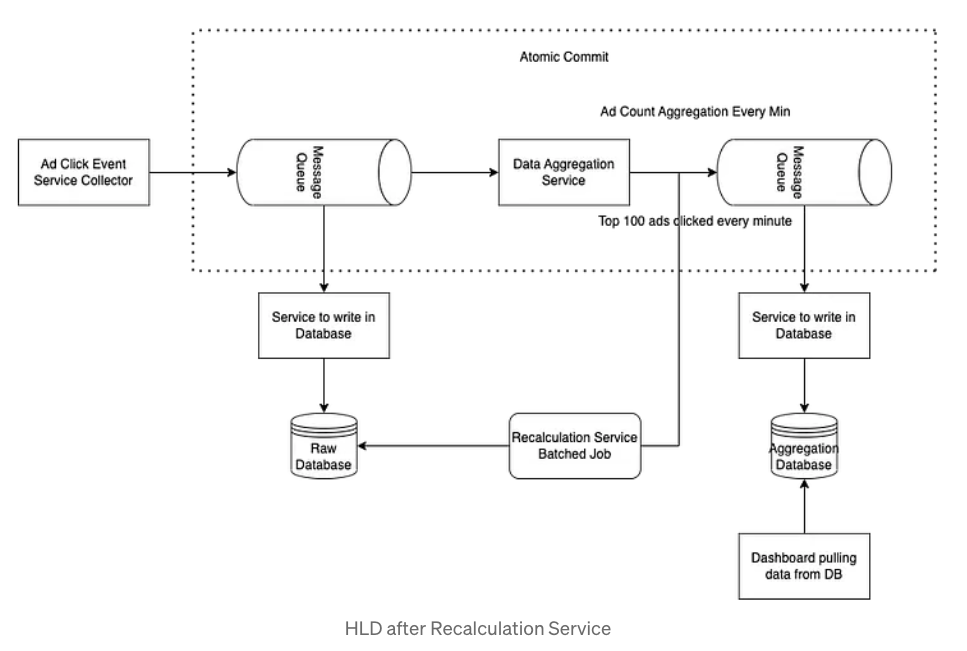
Q. 집계 서비스를 위해 어떤 "시간"을 기준으로 해야 하나? 이벤트 시간인가, 처리될 때의 시간인가?
이전 섹션을 기억해보면 집계 서비스는 매분 광고 클릭 이벤트를 집계한다. 두 가지 시간에 대해 정의해보자면,
- 이벤트 시간은 클라이언트로부터 이벤트가 발생한 시간을 의미한다. 즉, 유저가 특정 광고를 클릭한 시간이다.
- 처리될 때의 시간은 집계 서비스에서 광고 클릭 이벤트를 처리할 때의 시간이다.
두 가지 모두 장단점이 있으므로 각각 자세히 살펴본다.처리 시간을 기준으로 했을 때의 주요 결점 중 하나는 이벤트가 늦게 도착하는 경우이다. 서버는 특정 이벤트가 늦었다는 사실을 감지할 수 없으며 이는 결과가 부정확해지는 결과를 초래한다. 반면 이벤트 시간을 사용하는 경우 늦게 도착하는 이벤트를 자체적으로 처리해야 하는데 이는 쉬운 작업이 아니며 유저가 잘못된 이벤트 시간을 생성할수도 있다. 우리는 데이터 정확성이 필요하므로 이 모든것을 염두에 두고 이벤트 시간을 기준으로 사용하겠다.
그렇다면 늦게 도착한 이벤트는 어떻게 다뤄야 할까? 바로 워터마크를 사용하는 것이다. 우리는 모든 이벤트의 진행 상황을 추적하기 위해 워터마크를 정의한다. 이는 기본적으로 시스템에서 어느정도의 지연이 허용되는지에 대한 것이다. 모든 집계는 Tumbling window 방식으로 발생된다. Tumbling window를 단순화하기 위해 다른 window를 사용하기도 한다. 그리고 window를 연장하면 15초 내에 지연되는 모든 이벤트가 현재 window에 포함될 수 있다.
워터마크를 얼마나 많은 시간동안 설정해야하는지는 사용 사례에 따라 다르다. 너무 작으면 데이터 정확도가 저하될 수 있지만 대기시간은 짧아진다. 너무 크면 데이터 정확도는 문제가 되지 않지만 대기시간은 길어진다.
이러한 정확성을 수정하기 위해 재계산 서비스가 있으므로 항상 약간의 부정확성은 있을 수 있다. 여기서 다루기에는 너무 많은 세부사항이 존재하여 시스템 설계에서 벗어나므로 이에 대해 길게 다루지는 않는다.
다음으로, 모든 이벤트가 처리된다는 것을 어떻게 보장할 수 있을까? 그리고 모든 이벤트가 중복없이 정확히 한번만 처리된다는 것을 어떻게 보장할 수 있을까? 우리 시스템에서는 데이터 부정확성을 허용할 수 없으므로 위 질문을 자세히 답변하는것은 굉장히 중요하다.
다음처럼 중복 이벤트가 발생하는 두 가지 케이스가 있다.
- 클라이언트가 이벤트를 중복으로 보낸다. (또는 악의적인 사용자일수도 있다)
- 서버의 중단. 메시지를 컨슈밍한 이후 카프카 프로듀서에게 메시지를 커밋하기 전에 집계 서비스에 문제가 발생하는 경우 카프카 프로듀서는 모든 메시지를 다시 보내므로 중복 처리가 수행된다.
가장 확실한 방법은 오프셋을 HDFS와 같은 외부 저장소에 기록하는 것이다. 물론 이 접근 방식에도 문제가 있다. 아래의 그림을 보자.
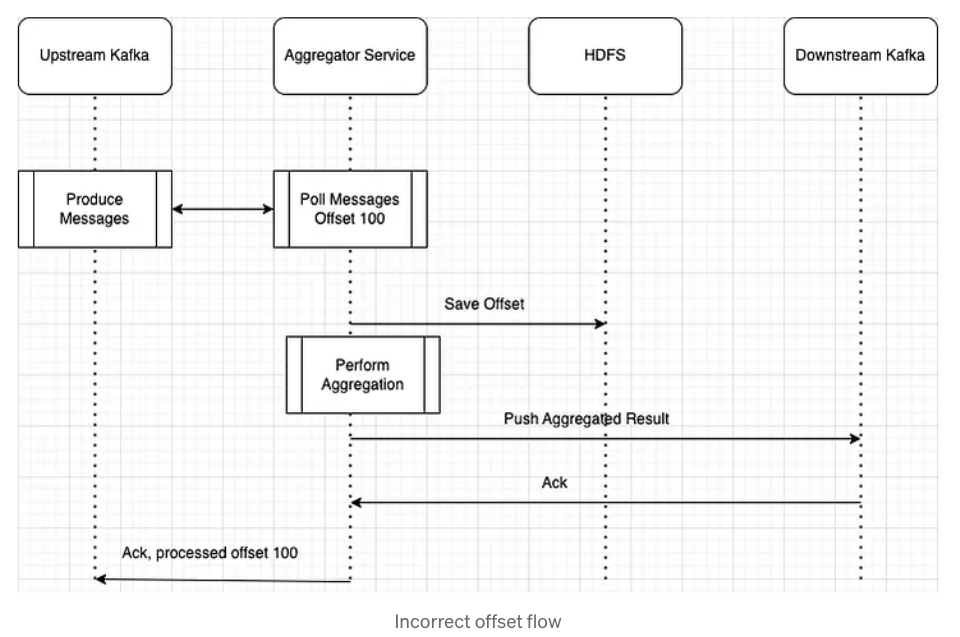
어그리게이터는 HDFS에 저장된 마지막 오프셋을 기준으로 메시지를 읽는다. 어그리게이터가 실패하더라도 오프셋 100까지 메시지를 소비했으므로 어그리게이터는 오프셋 100에서 다시 시작한다.
그러나 문제는 어그리게이트 결과를 카프카에 밀어넣기 전 오프셋을 저장하는 부분에서 발생한다. 오프셋을 저장한 후 어그리게이터가 실패하면 어떻게 될까? 처리된 모든 데이터는 유실되며 오프셋이 커밋되었으므로 어그리게이터는 유실된 데이터를 다시 처리하지 않는다. 그러므로 카프카에 데이터를 밀어넣은 이후 오프셋을 저장해야한다.

Scaling our Kafka Queue components
주요 몇가지 사항에 대해 이야기한다.
- 동일한 ad_id는 동일한 파티션으로 전달되는것이 중요하기 때문에 ad_id를 해싱하여 파티션을 결정한다. 그리고 각 컨슈머를 파티션들에 매핑하여 모든 광고 클릭 이벤트는 동일한 컨슈머가 가져가도록 한다. 이를 통해 데이터 부정확성을 방지한다.
- 서비스 런칭 이후 파티션을 변경하는 것은 복잡하기 때문에 미리 필요한 수의 파티션을 미리 생성해야 한다.
- 하나의 토픽만 만드는 것은 부족하므로 지역이나 기기에 따라 토픽을 나눠서 만드는것이 좋다.
Scale the Aggregation Service
집계 서비스는 Stateless하기 때문에 손쉽게 수평 확장이 가능하다. 필요에 따라 추가하거나 삭제도 가능하다. 만약 집계 서비스의 처리량을 늘리려면 어떻게 해야 할까?
- 옵션 1: 서로 다른 ad_id를 가진 이벤트를 서로 다른 스레드에 할당하고 병렬 처리한다.
- 옵션 2: Apache Hadoop Yarn등을 사용하여 집계 서비스를 배포한다. 이는 멀티 프로세스 시스템으로 높은 처리량을 보장한다.
실제로는 옵션 2를 가장 많이 사용한다.
Scale the Database
Cassandra는 기본적으로 Consistent hasing과 유사한 방식으로 수평 확장을 지원한다. 데이터는 적절한 내결함성을 통해 모든 노드에 고르게 분산된다. 각 노드는 링의 해시값을 기반으로 데이터를 저장하고 가상 노드를 기반으로 복사본도 저장한다. 시스템에 새로운 노드를 추가하면 노드 간 모든 가상 노드의 균형이 자동으로 조정되므로 Resharding이 필요하지 않다.
Q. 핫스팟은 어떻게 다뤄야 하나?
인기 있는 일부 광고는 특정 광고에 비해 많은 이벤트가 들어올 수 있다. 이에 대한 한가지 방법은 좀 더 많은 집계 노드를 해당 광고에 할당하는 것이다. 그러나 스케일링 전 어떤 광고가 인기가 많은지 식별해야한다. 따라서 사전에 테스트를 수행하고 Tumbling window에서 각 어그리게이터 노드가 처리할 수 있는 이벤트 수를 결정해야 한다. 예를 들어 Tumbling window가 300이라고 가정해보자. 300보다 많은 이벤트를 수신하면 어그리게이터 노드는 Yarn에게 더 많은 노드를 할당해달라고 요청하며 데이터는 할당된 여러 어그리게이터 노드에서 계산된다. 그리고 계산된 결과는 원래 노드로 기록된다. Global Local Aggregation 및 Split Distinct Aggregation과 같은 보다 정교한 기술이 있지만 여기에서 다루지는 않는다.
Fault tolerance
이제 확장성에 대해 살펴보았으므로 각 시스템에 장애가 발생할 경우 어떤 일이 발생하고 어떻게 복구할 것인지 논의하는 것도 중요하다. 내결함성에 대해 논의해야할 유일한 요소는 집계 서비스이다. 다른 서비스는 관리형 서비스이기에 자체 복구 시스템이 제공되기 때문이다.
만약 집계 서비스에 장애가 발생하면 HDFS에 저장된 마지막 오프셋을 통해 복구가 가능하다. 그런 다음 커밋된 오프셋에서 Kafka 브로커를 사용하여 집계 결과를 다시 저장할 수 있다. 하지만 이 접근 방식은 전체 결과를 다시 만들어야 하므로 약간의 시간이 걸릴 수 있다. 이러한 경우 오프셋과 함께 HDFS에 스냅샷을 함께 저장하는것이 좋다.
Data Integrity: Reconciliation Service
모든 스트리밍 서비스는 데이터 불일치가 있는지 확인하는 기능이 있다. 데이터 무결성을 달성하기 위해 할 수 있는 작업은 다음과 같다. 야간에 배치 작업을 통해 집계 데이터베이스와 로우 데이터가 저장된 데이터베이스 사이에 차이점이 있는지 확인하는 것이다. 보다 높은 요구사항을 위해 1시간과 같은 작은 window 크기로 데이터를 확인해도 된다.
여기까지 최종 디자인을 그려보면 다음과 같다.

Reference
https://medium.com/@nvedansh/system-design-ad-click-event-aggregation-8fb6aa7817fc
'Coding > 시스템 디자인' 카테고리의 다른 글
| 틴더(Tinder) 시스템 디자인 (0) | 2024.05.16 |
|---|---|
| Uber는 어떻게 Redis를 통해 초당 4천만 읽기를 제공하는가 (1) | 2024.05.07 |
| 결제 시스템 디자인 (0) | 2023.12.18 |
| 채팅 서비스 시스템 디자인 (0) | 2023.12.13 |
| Whatsapp(왓츠앱) 시스템 디자인 (0) | 2023.11.30 |



