2020년 우버는 Docstore라는 분산 데이터베이스를 출시했다. 이는 MySQL을 기반으로 만들어졌으며 초당 수천만건의 요청을 처리하는 동시에 페타바이트의 데이터를 저장할 수 있었다. 수년에 걸쳐 Docstore는 우버의 모든 비즈니스 분야에서 서비스 구축을 위해 사용되었고 이러한 어플리케이션의 대부분은 낮은 레이턴시와 높은 성능, 그리고 확장성을 요구했다.
Challenges with Low latency database reads
확장성이 높고 낮은 읽기 지연이 필요한 애플리케이션을 처리할 때 대다수의 데이터베이스는 문제를 맞이한다. 그 중 몇가지는 다음과 같다.
- 디스크에서 데이터를 검색하는 속도는 임계값이 있다. 또한 어플리케이션의 데이터 모델과 쿼리를 최적화하여 대기 시간을 개선하는 것에도 임계값은 존재한다.
- 수직 확장은 사양을 업그레이드하여 더 많은 리소스를 할당시킬 수 있지만 결국 병목은 데이터베이스이다.
- 데이터베이스를 여러 파티션으로 분할하여 수평 확장하는 것은 괜찮은 접근 방식이다. 그러나 시간이 지남에 따라 운영적으로 복잡해지고 핫 파티션과 같은 문제를 제거할 수 없다.
- 수직/수평 확장 전략 모두 장기적으로 비용이 많이 든다. 참고로 두 지역에 걸쳐 3개의 상태 저장 노드를 처리하기 위해서는 6배 정도의 추가적인 비용이 든다.
이러한 문제를 극복하기 위해 마이크로서비스는 일반적으로 캐싱을 활용한다. 우버는 다양한 팀을 위한 분산 캐싱 솔루션으로 레디스를 제공하기 시작했다. 서비스가 캐시에서 직접 읽기를 제공하면서 데이터베이스와 캐시에 쓰는 일반적인 패턴을 따랐다. 이는 아래와 같다.
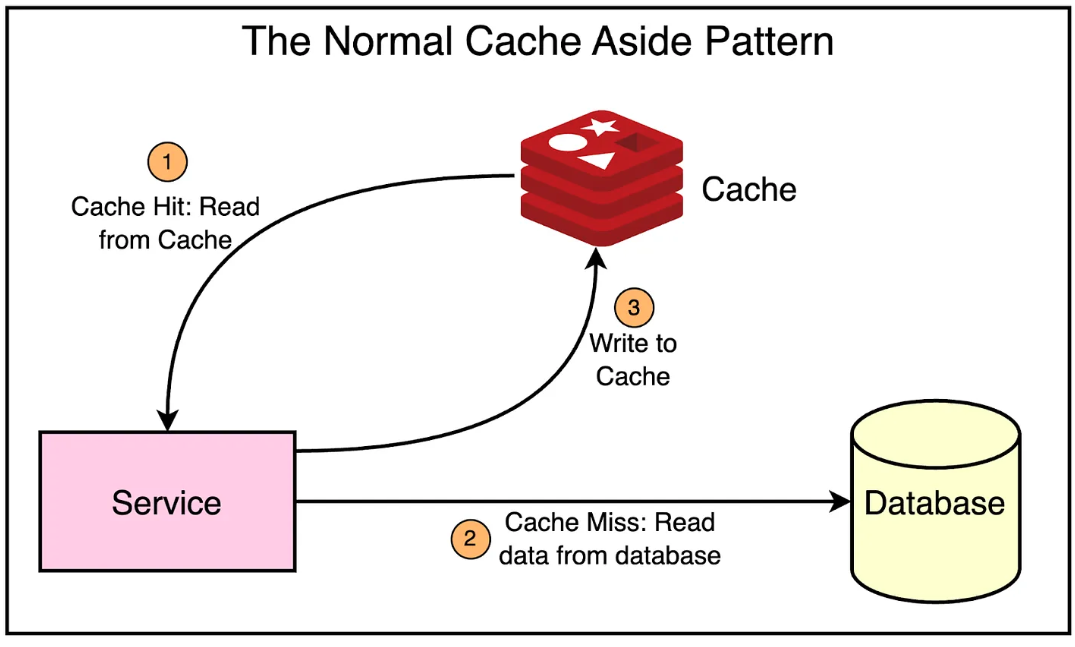
그러나 각 서비스가 캐시를 관리하는 일반적인 캐싱 패턴은 우버의 스케일에서 몇가지 문제를 가지고 있다.
- 각 팀이 각자의 레디스 클러스터를 관리 및 운영해야한다.
- 캐시 무효화 로직이 여러 마이크로서비스에 걸쳐 중복되므로 편차가 발생할 수 있다.
- 서비스는 fail over가 발생할 경우에도 핫 상태를 유지하기 위해 캐시 복제를 유지해야 한다.
가장 큰 문제는 캐싱이 필요한 모든 팀이 각자의 캐싱 솔루션을 구축하고 유지보수하는데에 많은 노력을 기울여야 한다는 것이다. 이를 방지하기 위해 우버는 CacheFront라는 통합 캐싱 솔루션을 구축하였다.
Design Goals with CacheFront
CacheFront를 구축하는 동안 우버는 몇가지 중요한 점들을 설계 목표로 삼았다.
- 짧은 읽기 지연을 지원하기 위해 수직 또는 수평 확장의 필요성을 줄인다.
- P50, P99 레이턴시를 개선하고 레이턴시가 튀는(스파이크) 현상을 개선한다.
- 데이터베이스 엔진 레벨에 대한 리소스 할당을 낮춘다.
- 각자 팀의 요구사항에 따라 커스텀하게 만들어진 캐싱 솔루션을 교체한다. 대신 레디스를 유지보수하는 오너십을 Docstore팀으로 옮긴다.
- 서비스 관점에서 캐싱을 투명하게 만들어 각자의 팀은 비즈니스 로직에만 집중할 수 있도록 한다.
- 핫 파티션을 방지하기 위해 Docstore의 파티셔닝 스키마에서 캐싱 솔루션을 분리한다.
- 저렴한 머신으로 캐싱 계층의 수평 확장성을 지원하고 전체 작업을 효율적인 비용으로 관리할 수 있게 만든다.
High-Level Architecture with CacheFront
이러한 디자인 요구사항을 충족시키기 위해 우버는 Docstore에 연결된 통합 캐싱 솔루션을 만들었다.
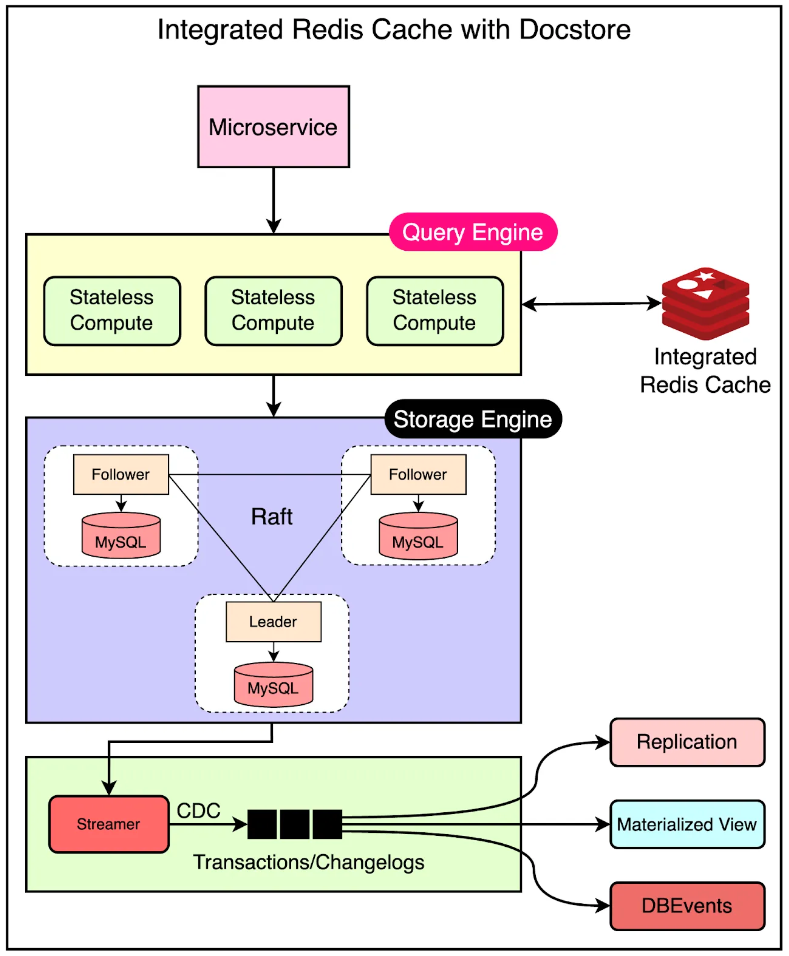
위에 나와있듯이 Docstore의 쿼리 엔진은 서비스를 위한 진입점으로 동작하며 클라이언트의 읽기/쓰기를 서빙하는 역할을 한다.
따라서 캐싱 계층을 통합하는것은 캐시를 디스크 기반 스토리지에서 분리할 수 있는 이상적인 장소였다. 쿼리 엔진은 캐싱 데이터를 무효화하는 메커니즘과 함께 캐시된 데이터를 저장하기 위한 레디스의 인터페이스를 구현했다.
Handling Cached Reads
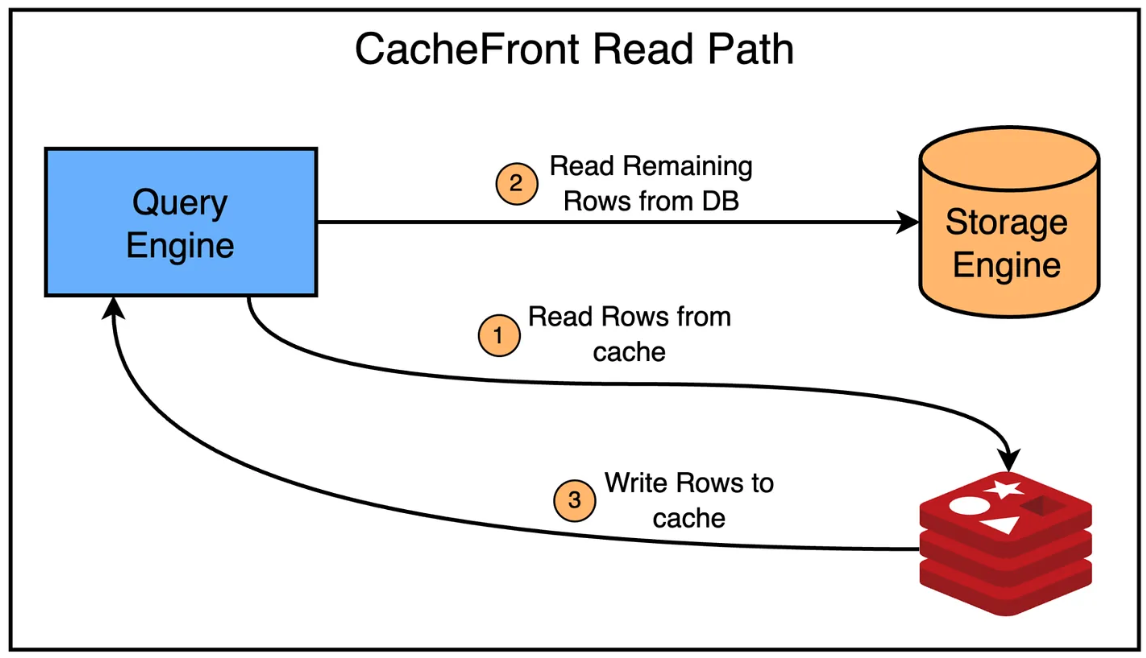
CacheFront는 읽기 요청을 위해 Cache-aside 또는 Look-aside 전략을 사용한다.
- 쿼리 엔진 계층은 하나 또는 여러개의 읽기 요청을 받는다.
- 쿼리 엔진은 레디스에서 데이터를 조회하고 유저에게 응답을 스트리밍한다.
- 다음으로 데이터베이스에서 데이터를 조회한다. (필요 시)
- 쿼리 엔진은 비동기적으로 레디스 캐시에 존재하지 않는 데이터를 적재한다.
- 남아있는 데이터를 유저에게 응답으로 스트리밍한다.
아래의 그림은 위 흐름을 좀 더 명확하게 보여준다.
Cache Invalidation with CDC
캐시 무효화는 컴퓨터 과학에서 어려운 문제이다. 가장 간단한 방법은 TTL을 설정하는 것이다. 이러한 방식은 여러가지 케이스에서 동작할 수 있지만 대부분의 사용자는 변경사항이 TTL보다 빠르게 반영되기를 원한다. 그러나 TTL값을 낮춘다면 캐시 히트율이 낮아지기 때문에 효율성 또한 적어진다.
우버는 캐시 무효화 효율성을 더욱 높이기 위해 Docstore의 CDC 스트리밍 서비스인 Flux를 활용했다. Flux는 MySQL의 binlog 이벤트를 추적하고 컨슈머에게 발행하는 방식으로 작동한다. 그리고 다양한 노드 간의 복제와 Materialized view, Data lake 및 데이터 일관성 검증등을 지원한다.
그리고 캐시 무효화를 데이터 변경 이벤트를 구독하고 레디스에서 데이터를 검증 및 Upsert하는 컨슈머가 필요하다. 아래의 그림은 위 과정을 상세하게 나타낸다.
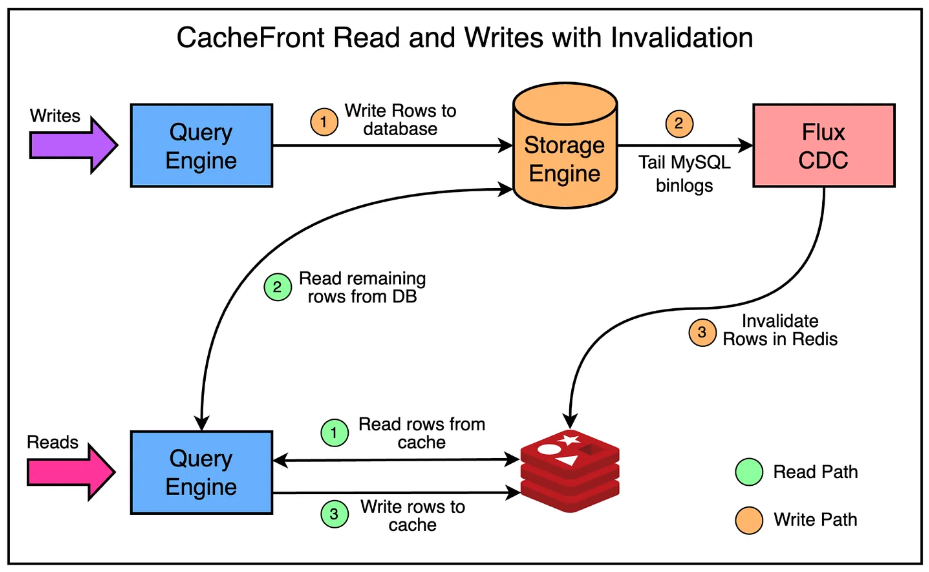
위 방법은 다음과 같은 주요 이점들이 있다.
- TTL에 따라 몇분이나 걸렸던 작업이 CDC로 인해 데이터베이스 변경 후 단 몇초만에 일관성을 유지할 수 있게 되었다.
- binlog를 사용함에 따라 커밋되지않은 트랜잭션이 레디스에 잘못된 데이터를 저장하는 케이스를 없앴다.
그러나 여기에도 해결해야할 몇가지 문제가 있었다.
1 - Deduplicating Cache Writes
쓰기 작업은 읽기와 쓰기 요청 사이에서 동시에 발생하기 때문에 이전 값이 최신 값을 덮어쓰는 경우가 있다. 이러한 문제를 방지하기 위해 MySQL에 설정된 행의 타임스탬프값을 기반으로 중복을 제거했다.
타임스탬프는 버전 번호로 사용되었으며 레디스의 EVAL 명령을 통해 인코딩된 데이터에서 파싱된다.
2 - Stronger Consistency Requirement
Flux를 이용한 CDC가 TTL보다 빠른 동기화를 보장함에도 불구하고 여전히 결과적 일관성을 제공한다는 문제는 동일하다. 그러나 몇몇의 유즈케이스들은 강한 일관성 보장이 필요했다.
따라서 해당 케이스들을 위해 쓰기가 완료된 직후 사용자가 캐시된 행을 명시적으로 무효화할 수 있도록 쿼리 엔진에 API를 만들어 제공했다. 이렇게 하면 CDC가 완료될 때 까지 기다릴 필요가 없었다.
Scale and Resiliency with CacheFront
CacheFront의 기본 요구사항은 읽기 및 캐시 무효화 지원을 통해 준비되었다. 하지만 우버는 이 솔루션이 Scalable하게 작동하기를 원했고 전체 플랫폼에 대한 복구 능력도 필요했다. 이러한 요구사항을 만족하기 위해 우버는 여러가지 전략을 활용했다.
Compare cache
측정은 시스템이 예상대로 동작하는지 검증하는 중요한 키포인트이다. CacheFront 또한 마찬가지였다. 우버는 캐시에 대한 읽기 요청을 Shadow하는 특수 모드를 CacheFront에 추가하여 캐시 데이터와 데이터베이스의 데이터가 정상적으로 동작하는지 확인할 수 있도록 했다. 불일치하는 로우가 존재하는 경우 분석을 위해 측정 항목으로 기록되도록 했다.
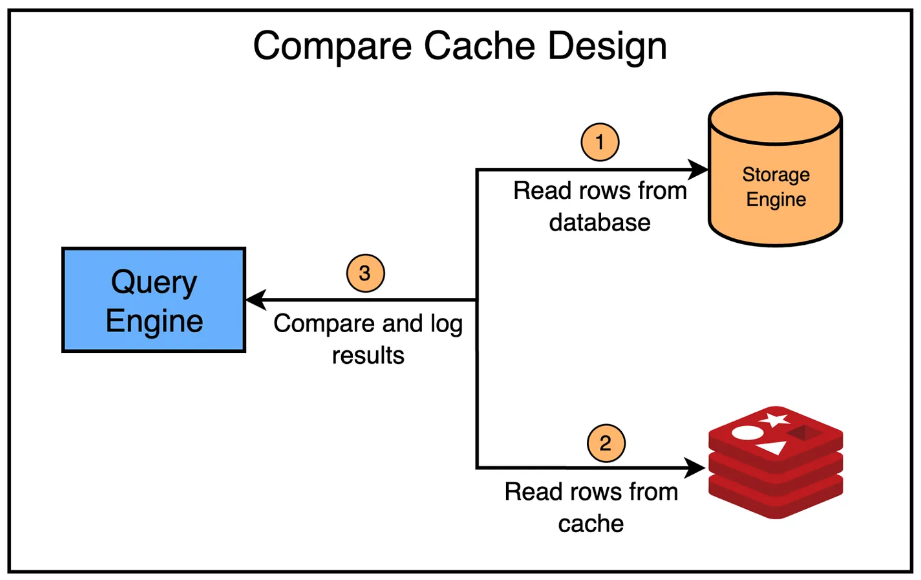
위 검증 과정을 통해 우버는 99.99%의 일관성을 유지했다.
Cache Warming
멀티 리전 환경의 경우 캐시는 warm상태일때만 효과적이다. 그렇지 않은 경우 region의 fail over는 캐시 히트율이 낮아지고 데이터베이스에 대한 요청이 크게 늘 수 있다.
Docstore 인스턴스는 Active-Active 이중화 상태로 서로 다른 리전에 배포되기 때문에 cold 캐시는 데이터베이스 부하가 높아질 가능성이 높고 이는 비용 절감을 위해 엔진의 스펙을 낮출 수 없음을 의미했다.
이 문제를 해결하기 위해 우버 엔지니어링팀은 크로스 리전 레디스 복제를 활용했다.
그러나 Docstore는 이미 자체적으로 크로스 리전 복제를 가지고 있었다. 두 복제 설정을 동시에 적용하면 캐시와 데이터베이스간 일관된 데이터가 생성될 수 있으므로 새로운 캐시 warm 모드를 추가하여 레디스 리전 간 복제 기능의 능력을 향상시켰다.
- 레디스 쓰기 스트림을 추적하여 다른 리전에 키를 복제한다.
- 다른 리전에서는 직접적으로 캐시를 업데이트하지 않는다. 대신 복제된 키에 대해 쿼리 엔진 계층에 읽기 요청을 보낸다.
- 캐시 미스의 경우 쿼리 엔진은 데이터베이스에서 데이터를 읽고 캐시에 데이터를 쓴다. 응답은 버려진다.
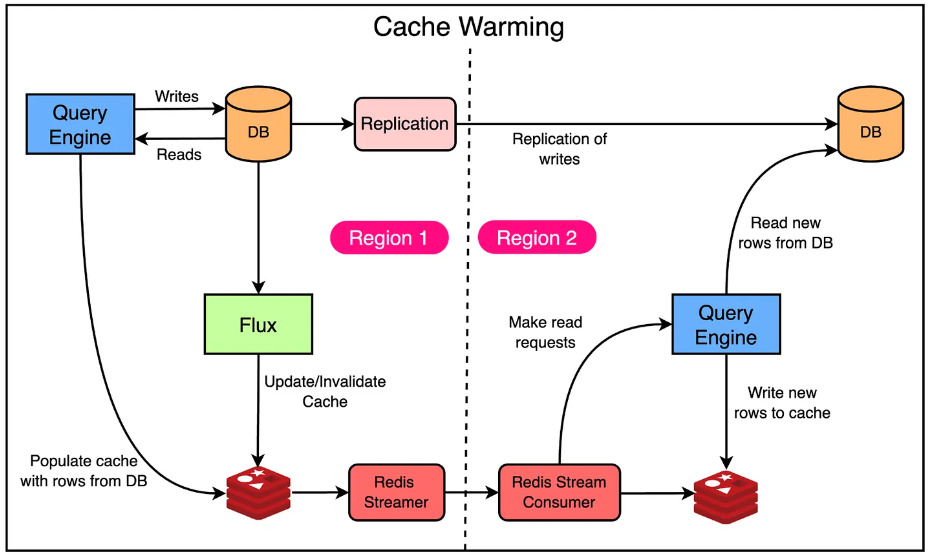
값 대신 키를 복제하면 캐시 데이터가 해당 지역의 데이터베이스 데이터와 일치하는지 확인할 수 있다. 또한 각 리전에서 동일한 데이터가 캐시되었는지 확인할 수 있고 그에 따라 failover를 대비하여 동일한 캐시를 유지할 수 있었다.
Sharding
우버에서 Docstore를 사용하는 특정 고객군의 경우 대량의 읽기/쓰기 요청을 발생시킬 수 있다. 이 때 최대 노드 수가 제한된 단일 레디스 클러스터 내에서 모든 것을 캐시하는 굉장히 어려운 일이다.
이를 해결하기 위해 단일 Docstore 인스턴스가 여러개의 레디스 클러스터에 매핑될 수 있도록 했다. 이는 단일 레디스 클러스터의 여러 노드가 다운되는 경우 데이터베이스에 대한 요청이 대량으로 급증하는 것을 방지하는데 도움이 되었다.
그러나 단일 레디스 클러스터가 다운되면 데이터베이스에 핫 샤드 문제가 발생할 수 있는 문제가 여전히 존재했다. 이를 방지하기 위해 데이터베이스 샤딩과는 다른 방식으로 레디스 클러스터를 샤딩했다. 이렇게 하면 단일 레디스 클러스터가 중단되어도 여러 데이터베이스 샤드간 요청이 분산된다.
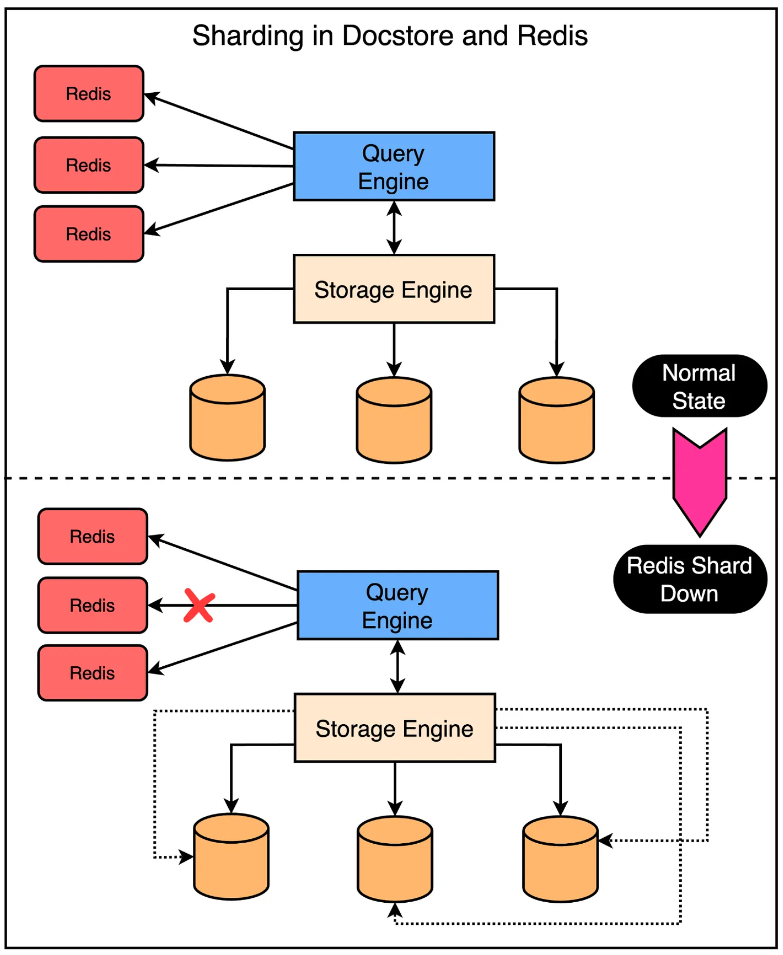
Circuit Breaker
레디스 노드가 다운되면 해당 노드에 대한 읽기/쓰기 요청으로 인한 불필요한 레이턴시 증가가 발생한다. 이를 방지하기 위해 우버는 요청에 대해 슬라이딩 윈도우 기반 서킷 브레이커를 도입했다. 이는 특정 시간동안 각 노드의 버킷에 쌓인 오류 수를 계산한다.
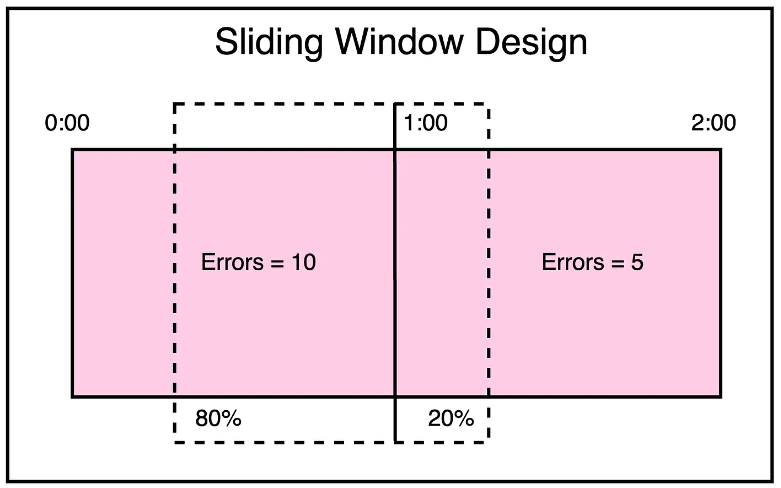
서킷 브레이커는 오류 수를 기준으로 노드에 대한 fraction으로 구성한다. 임계치에 도달하면 서킷 브레이커가 켜지고 윈도우가 지나갈 때 까지 해당 노드로 요청이 가지 않는다.
Results and Conclusion
우버의 레디스 캐시와 Docstore 통합 프로젝트는 꽤나 성공적이었다. 그들은 레이턴시를 개선하고 로드를 줄이며 비용을 절감하기 위해 확장 가능한 관리형 캐싱 솔루션을 만들었다. 이를 통해 아래의 성과를 거둘 수 있었다.
- P75 레이턴시는 75% 감소했고 P99.9 레이턴시는 67%감소했다.
- Flux 및 캐시 검증을 통한 캐시 무효화는 99.9%의 일관성을 제공했다.
- 샤딩과 캐시 warming 을 통해 확장성과 내결함성을 확보했고 이는 초당 600만이 넘는 요청에 대해 99.9%의 캐시 히트율을 달성했다.
- 기존에는 초당 600만의 읽기 요청의 경우 대략 60K CPU코어가 필요했지만 CacheFront를 통해 3K 레디스 코어만으로 동일한 결과를 얻을 수 있었다.
- 현재 CacheFront는 프로덕션 환경에서 초당 4천만개가 넘는 요청을 지원하며 현재도 요청수는 증가하고 있다.
Reference
https://blog.bytebytego.com/p/how-uber-uses-integrated-redis-cache
'Coding > 설계 | 경험' 카테고리의 다른 글
| 틴더(Tinder) 시스템 디자인 (0) | 2024.05.16 |
|---|---|
| 결제 시스템 디자인 (0) | 2023.12.18 |
| 광고 클릭 이벤트 시스템 디자인 (0) | 2023.12.14 |
| 채팅 서비스 시스템 디자인 (0) | 2023.12.13 |
| Whatsapp(왓츠앱) 시스템 디자인 (0) | 2023.11.30 |

